Factor is faster than Zig!
Thursday, November 9, 2023
Recently, I was looking at the Zig programming language. As I often do, I started implementing a few typical things in new languages to learn them. Well, one of them was super slow and Zig is supposed to be super fast, so I was trying to understand where the disconnect was and compare it to Factor!
I was able to reduce the issue to a small test case and it turns out that there is a behavioral issue in their implementation of HashMap that makes their HashMaps get slow over time. The test case performs these steps:
- creates a
HashMapof 2 million items - decrements the map values, removing an item every third loop
- inserts a replacement new item to maintain 2 million items in the
HashMap - for a total of 250 million actions, then
- deletes the remaining items from the
HashMap
We record the total time each block of 1 million actions takes:
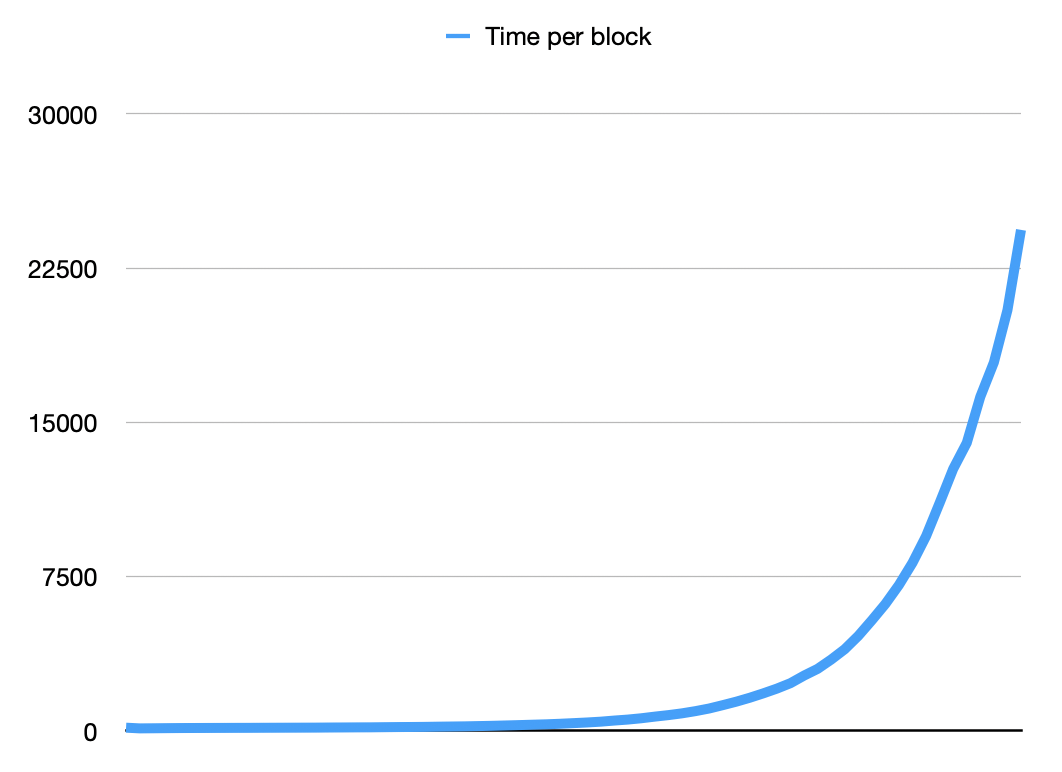
Something is very wrong!
Zig
This is the simple test case implemented in Zig using the std.HashMap:
const std = @import("std");
pub fn main() !void {
var map = std.AutoHashMap(u64, u64).init(std.heap.page_allocator);
defer map.deinit();
var list = std.ArrayList(u64).init(std.heap.page_allocator);
defer list.deinit();
var prng = std.rand.DefaultPrng.init(0);
const random = prng.random();
var start = std.time.milliTimestamp();
var i: u64 = 0;
while (i < 2_000_000) : (i += 1) {
try map.put(i, 3);
try list.append(i);
}
while (i < 250_000_000) : (i += 1) {
var index = random.uintLessThan(usize, list.items.len);
var j = list.items[index];
var k = map.get(j).?;
if (k == 1) {
_ = map.remove(j);
try map.put(i, 3);
list.items[index] = i;
} else {
try map.put(j, k - 1);
}
if (i % 1_000_000 == 0) {
var end = std.time.milliTimestamp();
std.debug.print("{} block took {} ms\n", .{ i, end - start });
start = std.time.milliTimestamp();
}
}
while (list.items.len > 0) {
var j = list.pop();
_ = map.remove(j);
}
}
We can run it using ReleaseFast to get the best performance and see
that, over time, it gets super slow – so slow that it isn’t even able to
really finish the test case:
$ zig version
0.11.0
$ zig run -O ReleaseFast maptest.zig
2000000 block took 156 ms
3000000 block took 122 ms
4000000 block took 127 ms
5000000 block took 133 ms
6000000 block took 138 ms
7000000 block took 141 ms
8000000 block took 143 ms
9000000 block took 145 ms
10000000 block took 147 ms
11000000 block took 148 ms
12000000 block took 151 ms
13000000 block took 153 ms
14000000 block took 155 ms
15000000 block took 157 ms
16000000 block took 159 ms
17000000 block took 164 ms
18000000 block took 167 ms
19000000 block took 171 ms
20000000 block took 173 ms
21000000 block took 180 ms
22000000 block took 186 ms
23000000 block took 190 ms
24000000 block took 195 ms
25000000 block took 205 ms
26000000 block took 213 ms
27000000 block took 221 ms
28000000 block took 234 ms
29000000 block took 247 ms
30000000 block took 264 ms
31000000 block took 282 ms
32000000 block took 301 ms
33000000 block took 320 ms
34000000 block took 346 ms
35000000 block took 377 ms
36000000 block took 409 ms
37000000 block took 448 ms
38000000 block took 502 ms
39000000 block took 550 ms
40000000 block took 614 ms
41000000 block took 694 ms
42000000 block took 767 ms
43000000 block took 853 ms
44000000 block took 961 ms
45000000 block took 1088 ms
46000000 block took 1250 ms
47000000 block took 1420 ms
48000000 block took 1612 ms
49000000 block took 1826 ms
50000000 block took 2056 ms
51000000 block took 2320 ms
52000000 block took 2688 ms
53000000 block took 3015 ms
54000000 block took 3467 ms
55000000 block took 3971 ms
56000000 block took 4618 ms
57000000 block took 5377 ms
58000000 block took 6172 ms
59000000 block took 7094 ms
60000000 block took 8173 ms
61000000 block took 9469 ms
62000000 block took 11083 ms
63000000 block took 12737 ms
64000000 block took 14000 ms
65000000 block took 16243 ms
66000000 block took 17912 ms
67000000 block took 20452 ms
68000000 block took 24356 ms
...
We can switch the example above to use std.ArrayHashMap which does not have
this problem, although it is a bit slower with each block taking roughly 250
milliseconds.
Factor
We can compare that to a simple implementation in Factor:
USING: assocs calendar formatting io kernel math random
sequences ;
:: maptest ( -- )
H{ } clone :> m
V{ } clone :> l
now :> start!
0 :> i!
[ i 2,000,000 < ] [
3 i m set-at
i l push
i 1 + i!
] while
[ i 250,000,000 < ] [
l length random :> j
j l nth :> k
k m at 1 - [
k m delete-at
3 i m set-at
i j l set-nth
] [
k m set-at
] if-zero
i 1,000,000 mod zero? [
i now start time- duration>milliseconds
"%d block took %d ms\n" printf flush
now start!
] when
i 1 + i!
] while
[ l empty? ] [
l pop m delete-at
] until ;
We can run it in Factor and see how long it takes. There are notably some long delays in the first few blocks which I’d like to understand better – possibly due to excessive rehashing or some allocation pattern with the Factor garbage collector – and then it quickly reaches a steady state where each block takes about 250 milliseconds.
$ factor maptest.factor
2000000 block took 855 ms
3000000 block took 198 ms
4000000 block took 205 ms
5000000 block took 3579 ms
6000000 block took 4438 ms
7000000 block took 3624 ms
8000000 block took 2996 ms
9000000 block took 232 ms
10000000 block took 243 ms
11000000 block took 248 ms
12000000 block took 298 ms
13000000 block took 233 ms
14000000 block took 238 ms
15000000 block took 298 ms
16000000 block took 233 ms
17000000 block took 521 ms
18000000 block took 231 ms
19000000 block took 236 ms
20000000 block took 280 ms
21000000 block took 235 ms
22000000 block took 235 ms
23000000 block took 281 ms
24000000 block took 231 ms
25000000 block took 236 ms
26000000 block took 294 ms
27000000 block took 231 ms
28000000 block took 236 ms
29000000 block took 506 ms
30000000 block took 234 ms
31000000 block took 237 ms
32000000 block took 277 ms
33000000 block took 232 ms
34000000 block took 239 ms
35000000 block took 279 ms
36000000 block took 235 ms
37000000 block took 239 ms
38000000 block took 275 ms
39000000 block took 234 ms
40000000 block took 514 ms
41000000 block took 231 ms
42000000 block took 236 ms
43000000 block took 282 ms
44000000 block took 235 ms
45000000 block took 235 ms
46000000 block took 282 ms
47000000 block took 231 ms
48000000 block took 233 ms
49000000 block took 280 ms
50000000 block took 234 ms
51000000 block took 238 ms
52000000 block took 507 ms
53000000 block took 231 ms
54000000 block took 236 ms
55000000 block took 276 ms
56000000 block took 231 ms
57000000 block took 238 ms
58000000 block took 278 ms
59000000 block took 234 ms
60000000 block took 235 ms
61000000 block took 278 ms
62000000 block took 237 ms
63000000 block took 239 ms
64000000 block took 510 ms
65000000 block took 234 ms
66000000 block took 284 ms
...
Not bad!
What’s the Bug?
So, Zig could be super fast, but the default std.HashMap implementation
uses tombstone buckets to mark slots as being deleted, and over time these
tombstone buckets create fragmentation in the HashMap, which causes their
linear probing to trend towards the worst case examination of every bucket in
the HashMap when looking for a key.
We can implement a rehash() method on the HashMap that performs an in-place
rehashing of all the elements, without allocations. Ideally, this would be done
when the number of filled and deleted slots reaches some capacity threshold.
But, for now, we can just run map.rehash() once per block, and see how that
improves performance:
diff --git a/lib/std/hash_map.zig b/lib/std/hash_map.zig
index 8a3d78283..7192ba733 100644
--- a/lib/std/hash_map.zig
+++ b/lib/std/hash_map.zig
@@ -681,6 +681,11 @@ pub fn HashMap(
self.unmanaged = .{};
return result;
}
+
+ /// Rehash the map, in-place
+ pub fn rehash(self: *Self) void {
+ self.unmanaged.rehash(self.ctx);
+ }
};
}
@@ -1505,6 +1510,92 @@ pub fn HashMapUnmanaged(
return result;
}
+ /// Rehash the map, in-place
+ pub fn rehash(self: *Self, ctx: anytype) void {
+ const mask = self.capacity() - 1;
+
+ var metadata = self.metadata.?;
+ var keys_ptr = self.keys();
+ var values_ptr = self.values();
+ var curr: Size = 0;
+
+ // While we are re-hashing every slot, we will use the
+ // fingerprint to mark used buckets as being used and either free
+ // (needing to be rehashed) or tombstone (already rehashed).
+
+ while (curr < self.capacity()) : (curr += 1) {
+ metadata[curr].fingerprint = Metadata.free;
+ }
+
+ // Now iterate over all the buckets, rehashing them
+
+ curr = 0;
+ while (curr < self.capacity()) {
+ if (!metadata[curr].isUsed()) {
+ assert(metadata[curr].isFree());
+ curr += 1;
+ continue;
+ }
+
+ var hash = ctx.hash(keys_ptr[curr]);
+ var fingerprint = Metadata.takeFingerprint(hash);
+ var idx = @as(usize, @truncate(hash & mask));
+
+ // For each bucket, rehash to an index:
+ // 1) before the cursor, probed into a free slot, or
+ // 2) equal to the cursor, no need to move, or
+ // 3) ahead of the cursor, probing over already rehashed
+
+ while ((idx < curr and metadata[idx].isUsed()) or
+ (idx > curr and metadata[idx].fingerprint == Metadata.tombstone))
+ {
+ idx = (idx + 1) & mask;
+ }
+
+ if (idx < curr) {
+ assert(metadata[idx].isFree());
+ metadata[idx].fingerprint = fingerprint;
+ metadata[idx].used = 1;
+ keys_ptr[idx] = keys_ptr[curr];
+ values_ptr[idx] = values_ptr[curr];
+
+ metadata[curr].used = 0;
+ assert(metadata[curr].isFree());
+ keys_ptr[curr] = undefined;
+ values_ptr[curr] = undefined;
+
+ curr += 1;
+ } else if (idx == curr) {
+ metadata[idx].fingerprint = fingerprint;
+ curr += 1;
+ } else {
+ assert(metadata[idx].fingerprint != Metadata.tombstone);
+ metadata[idx].fingerprint = Metadata.tombstone;
+ if (metadata[idx].isUsed()) {
+ var tmpkey = keys_ptr[idx];
+ var tmpvalue = values_ptr[idx];
+
+ keys_ptr[idx] = keys_ptr[curr];
+ values_ptr[idx] = values_ptr[curr];
+
+ keys_ptr[curr] = tmpkey;
+ values_ptr[curr] = tmpvalue;
+ } else {
+ metadata[idx].used = 1;
+ keys_ptr[idx] = keys_ptr[curr];
+ values_ptr[idx] = values_ptr[curr];
+
+ metadata[curr].fingerprint = Metadata.free;
+ metadata[curr].used = 0;
+ keys_ptr[curr] = undefined;
+ values_ptr[curr] = undefined;
+
+ curr += 1;
+ }
+ }
+ }
+ }
+
oid {
@setCold(true);
const new_cap = @max(new_capacity, minimal_capacity);
@@ -2218,3 +2309,35 @@ test "std.hash_map repeat fetchRemove" {
try testing.expect(map.get(2) != null);
try testing.expect(map.get(3) != null);
}
+
+test "std.hash_map rehash" {
+ var map = AutoHashMap(u32, u32).init(std.testing.allocator);
+ defer map.deinit();
+
+ var prng = std.rand.DefaultPrng.init(0);
+ const random = prng.random();
+
+ const count = 6 * random.intRangeLessThan(u32, 100_000, 500_000);
+
+ var i: u32 = 0;
+ while (i < count) : (i += 1) {
+ try map.put(i, i);
+ if (i % 3 == 0) {
+ try expectEqual(map.remove(i), true);
+ }
+ }
+
+ map.rehash();
+
+ try expectEqual(map.count(), count * 2 / 3);
+
+ i = 0;
+ while (i < count) : (i += 1) {
+ if (i % 3 == 0) {
+ try expectEqual(map.get(i), null);
+ } else {
+ try expectEqual(map.get(i).?, i);
+ }
+ }
+}
We can apply that diff to lib/std/hash_map.zig and try again, now taking
about 165 milliseconds per block including the time for map.rehash():
$ zig run -O ReleaseFast maptest.zig --zig-lib-dir ~/Dev/zig/lib
2000000 block took 155 ms
3000000 block took 147 ms
4000000 block took 154 ms
5000000 block took 160 ms
6000000 block took 163 ms
7000000 block took 164 ms
8000000 block took 165 ms
9000000 block took 166 ms
10000000 block took 166 ms
11000000 block took 165 ms
12000000 block took 166 ms
13000000 block took 165 ms
14000000 block took 166 ms
15000000 block took 172 ms
16000000 block took 165 ms
17000000 block took 167 ms
18000000 block took 165 ms
19000000 block took 167 ms
20000000 block took 169 ms
21000000 block took 168 ms
22000000 block took 167 ms
23000000 block took 166 ms
24000000 block took 167 ms
25000000 block took 167 ms
26000000 block took 165 ms
27000000 block took 166 ms
28000000 block took 166 ms
29000000 block took 165 ms
30000000 block took 165 ms
31000000 block took 165 ms
32000000 block took 166 ms
33000000 block took 165 ms
34000000 block took 167 ms
35000000 block took 170 ms
36000000 block took 165 ms
37000000 block took 166 ms
38000000 block took 166 ms
39000000 block took 164 ms
40000000 block took 165 ms
41000000 block took 167 ms
42000000 block took 166 ms
43000000 block took 167 ms
44000000 block took 169 ms
45000000 block took 166 ms
46000000 block took 165 ms
47000000 block took 166 ms
48000000 block took 166 ms
49000000 block took 166 ms
50000000 block took 166 ms
51000000 block took 166 ms
52000000 block took 164 ms
53000000 block took 165 ms
54000000 block took 167 ms
55000000 block took 165 ms
56000000 block took 166 ms
57000000 block took 166 ms
58000000 block took 165 ms
59000000 block took 166 ms
60000000 block took 169 ms
61000000 block took 165 ms
62000000 block took 165 ms
63000000 block took 166 ms
64000000 block took 166 ms
65000000 block took 165 ms
66000000 block took 166 ms
67000000 block took 176 ms
68000000 block took 166 ms
...
Well now, Zig is fast and everything is right again with the world – and
Factor takes only about 50% more time than Zig’s std.HashMap with
rehash() and about the same as std.ArrayHashMap, which is pretty
good for a dynamic language.
I submitted a pull request adding a rehash() method to HashMap and hopefully it gets into the upcoming Zig 0.12 release and maybe for Zig 0.13 they can adjust it to automatically rehash when it gets sufficiently fragmented, consider using quadratic probing instead of linear probing, or perhaps switch to using a completely different HashMap algorithm like Facebook’s F14 hash table, which doesn’t have this issue.
Maybe we should consider some of these improvements for Factor as well!
Open source is fun!