Reddit "Top"
Monday, January 17, 2011
Reddit has an
API that can be used for accessing
much of the information available through their website. We can retrieve
a JSON list of recent stories posted to any
subreddit by going to https://api.reddit.com/r/$NAME. You can
experiment with this in the Factor
listener - to retrieve top stories for the
programming subreddit:
IN: scratchpad USING: http.client json.reader ;
IN: scratchpad "https://api.reddit.com/r/programming"
http-get nip json> .
Someone once used the API to build a reddit-top program for monitoring top stories from the console. We will use Factor vocabularies to scrape Reddit and produce something similar:
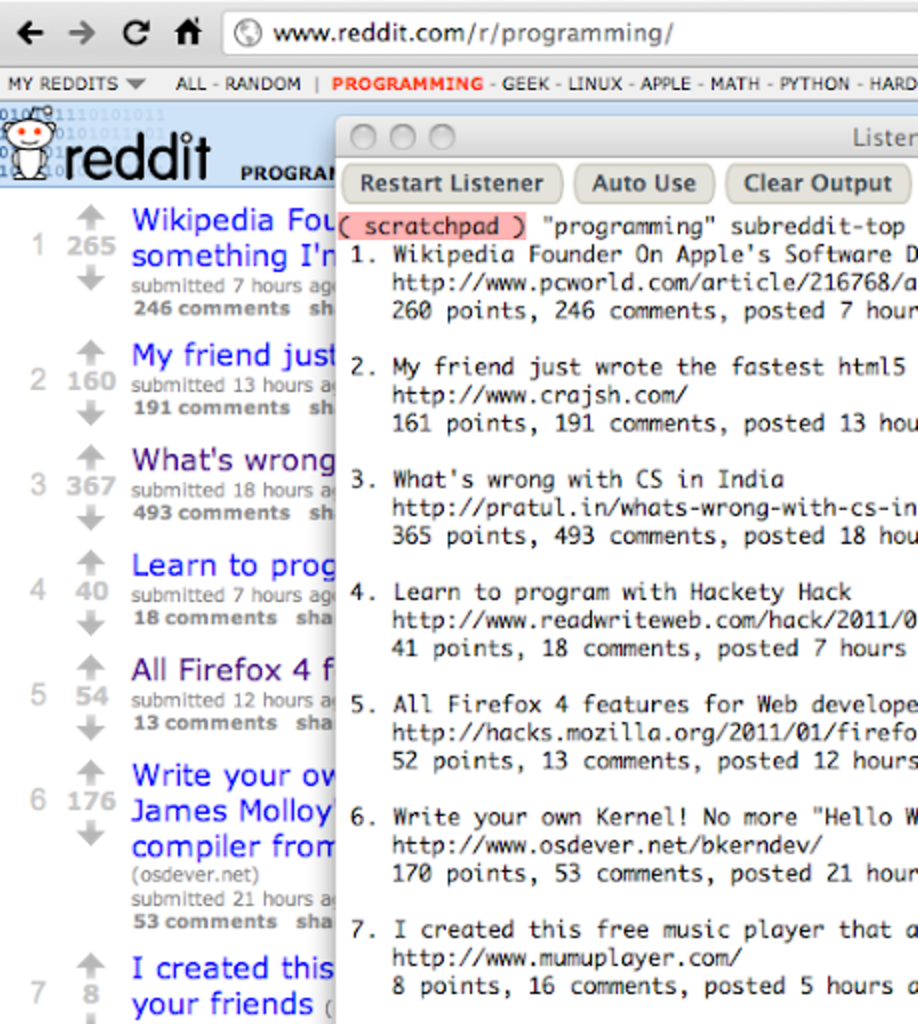
We start by building a (subreddit) helper word to retrieve the JSON
response for a particular subreddit, extracting the top stories, and
returning an array of hashtables (one for each of the top stories).
: (subreddit) ( name -- seq )
"https://api.reddit.com/r/%s" sprintf http-get nip
json> { "data" "children" } [ swap at ] each
[ "data" swap at ] map ;
We can then define a story tuple, with a slot for each attribute
returned by the API.
TUPLE: story author clicked created created_utc domain downs
hidden id is_self levenshtein likes media media_embed name
num_comments over_18 permalink saved score selftext
selftext_html subreddit subreddit_id thumbnail title ups url ;
Once we have that, we can use the set-slots word from my previous post
on setting
attributes
to build a subreddit word that retrieves the top stories as objects:
: subreddit ( name -- stories )
(subreddit) [ story new [ set-slots ] keep ] map ;
Thats all we need to build the subreddit-top word demonstrated in the
beginning:
- Retrieve the top stories for a given subreddit.
- Loop over each story.
- Format and print the relevant attributes.
: subreddit-top ( subreddit -- )
subreddit [
1 + "%2d. " printf {
[ title>> ]
[ url>> ]
[ score>> ]
[ num_comments>> ]
[
created_utc>> unix-time>timestamp now swap time-
duration>hours "%d hours ago" sprintf
]
[ author>> ]
} cleave
"%s\n %s\n %d points, %d comments, posted %s by %s\n\n"
printf
] each-index ;
This (and some code for users and comments) is available on my GitHub.